摘要:Fuzz技术发展很快,被开发者拿来在开发过程中进行软件测试。但也被攻击者拿来挖0 day漏洞,这很危险,所以亟需一个反模糊测试技术,作者提出了fuzzifacation,保护发行的只有二进制的程序免受攻击者在其上应用先进的模糊测试技术,只需要很小的性能消耗就能尽可能阻碍模糊测试。
Fuzzification涉及到三项技术:
- SpeedBump:将正常执行的减速放大了数百倍,以阻碍模糊执行
- BranchTrap:通过隐藏路径和污染覆盖图干扰代码覆盖率与路径的反馈信息
- AntiHybrid:妨碍污点分析和符号执行
每种技术都采用尽力而为的防御措施设计,试图阻止对手绕过FUZZIFICATION。
在流行的模糊测试技术与现实世界程序上的实验评估表明,减少了70.3%的路径发现,以及93.0%的现实二进制程序的已确认的crash发现。文中还讨论了工具针对对手分析技术的鲁棒性,开源。
introduction
Fuzz现在被拿来作为发现复杂的现代软件漏洞的标准操作。然而攻击者也更加的倾向于用fuzz去挖0 day漏洞,研究表明fuzz技术比静态分析或人工检测挖出4.83倍之多的漏洞。所以对开发者来说,将抗fuzz技术应用于产品十分重要(与将混淆应用于逆向工程相似)。
本文提出了一种二进制保护的新方向,Fuzzification,阻止攻击者高效的发掘bug。尽管对被Fuzzification保护的程序,攻击者仍然能够发掘bug,但需要花费更多的资源(CPU 内存以及时间等)。
Fuzzification应该有以下三个特性:
- 高效的阻碍现有的模糊测试工具
- 被保护的程序应该仍然以正常水平高效运行
- 保护代码不应该很容易的移除被分析技术直接移除
据他所知,现在没有技术能做到。
- 软件混淆技术:
- 减慢了正常的执行
- 使用UPX时,至少慢了1.7倍
- 使用LLVM混淆器时,慢了超过25倍
- 无法阻止路径探索,fuzz对路径的探索与测试正常程序几乎完全一样
- 减慢了正常的执行
- 软件的多样化版本分发(改变目标程序的数据结构与接口)
- 在攻击者分析时隐藏原始漏洞的能力上无力
以上技术都不太行。
Fuzzification:SpeedBump/BranchTrap/AntiHybrid
- SpeedBump
- 减缓程序在模糊测试时的执行速度
- 对cold path注入延迟(正常程序很少到达,fuzz经常到达)
- BranchTrap
- 插入大量输入敏感的跳转,任意输入漂移会显著改变执行路径
- 将基于代码覆盖率的模糊测试技术引导至花费更多努力在bug-free的路径上
- AntiHybrid
- 阻挠传统fuzz与动态污点及符号执行的结合
并且针对攻击者可能分析移除保护代码,做了工作:
- SpeedBump
- 不使用sleep,而是在cold path注入随机的占用CPU资源的指令
- 创建注入代码与原始代码之间的控制流与数据流依赖
- BranchTrap
- 重用现有的二进制代码去实现,防止对手识别出注入的分支
- AntiHybrid
- ????
在LAVA-M和9个实际程序(libjpeg, libpng, libtiff, pcre2, readelf, objdump, nm, objcopy 和 MuPDF)上做了评估(这些程序经常被用来评估fuzz)。
使用了AFL/HonggFuzz/VUzzer/QSYM,相比保护后的程序,
- 平均多发现了14.2倍多的bug
- LAMA-M上平均多发现了3倍的bug
- 路径发现减少了70.3%
- 并且保持了用户指定的开销预算
- 作者还进行了分析,以显示数据流和控制流分析技术无法轻松撤消保护技术
贡献如下:
- 首先阐明了反模糊方案的新研究方向,即Fuzzification
- 开发了Fuzzification技术,减慢模糊测试每次执行的速度,隐藏了路径覆盖,阻碍动态污点分析与符号执行
- 根据流行的模糊测试工具和通用基准评估了技术,发现的错误减少了93%,从LAVA-M数据集中发现的错误减少了67.5%,代码覆盖减少了70.3%,同时保持了用户指定的开销预算
- 开源
背景与难题
Fuzz技术
不用多说
通过快速执行进行模糊测试
最直接的提高fuzz效率:使每次执行更快。诸如:大规模并行测试/AFL的fork server减少进程的产生/AFL-PT,kAFL,Honggfuzz使用pt技术和bts技术高效收集代码覆盖指导fuzz/Xu等设计了新的操作系统原语,例如有效的系统调用,以加快多核计算机上的模糊测试。
覆盖率指导模糊测试
对每次执行收集代码覆盖率指导fuzz(基于两个观点:高覆盖率更高可能发现bug;发现新路径的输入更可能发现其他新路径)
覆盖率表示
- 基本块覆盖率:Honggfuzz 与VUzzer
- 分支覆盖率:AFL
- Angora:结合分支覆盖率与调用栈
覆盖率表示的选择是一个性能与覆盖准确度的权衡:更细粒度的覆盖准确性需要更高的开销,导致fuzz效率低
覆盖率收集
- 有源代码,在编译时处理,libfuzzer AFL-LLVM 模式
- 否则采取动态或静态方法,AFL-QEMU
- 利用硬件特性 pt(PT-fuzzer,kAFL,Honggfuzz)
利用数据结构保存覆盖率
- 固定大小数组 :AFL ,Honggfuzz
- VUzzer python的set(集合)数据结构
数据结构的大小也是一个准确性和性能的平衡:太小不能捕捉每个覆盖变化;太大开销显著(AFL 的bitmap从64KB变成1MB后性能下降30%)
混合方法的模糊测试
解决现有模糊测试技术的限制
- fuzzer不区分输入的类型(magic number 或者 长度等),花费时间变异不影响控制流的不重要的字节,因此引入污点分析判断哪些输入用来决定分支走向(VUzzer)
- fuzzer无法解决复杂的条件,magic value与校验和检查,使用符号执行去解决
FUZZIFICATION 问题
fuzzificatioN工作流程如图:
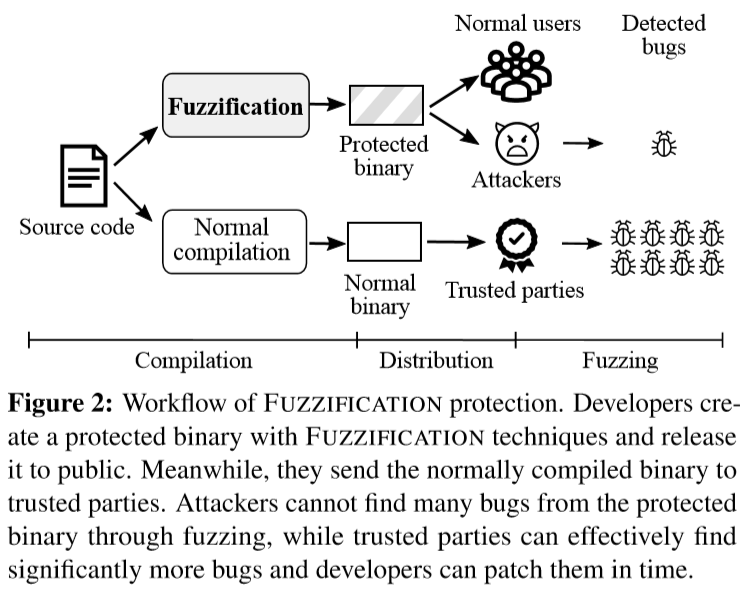
源代码编译成两种版本
- 使用fuzzification的版本:发布
- 正常版本:交给信任方用来测试
威胁模型
- 攻击者利用先进的模糊测试技术,但计算资源有限
- 攻击者有受保护的二进制文件
- 攻击者知道fuzzification技术
- 可以使用现成的二进制分析技术尝试从受保护的二进制文件中消除FUZZIFICATION
可以访问不受保护的二进制文件甚至访问程序源代码的攻击不在范围内。
设计目标与选择
- 有效:有效的减少被保护二进制程序的bug被发现数量
- 通用:应对大多数模糊测试技术的基础原则
- 高效:给正常执行带来最小的开销
- 鲁棒性:对尝试通过分析方式将其从被保护二进制中移除具有抵抗性
根据以上目标,检查了四个阻碍恶意fuzz的设计选择:
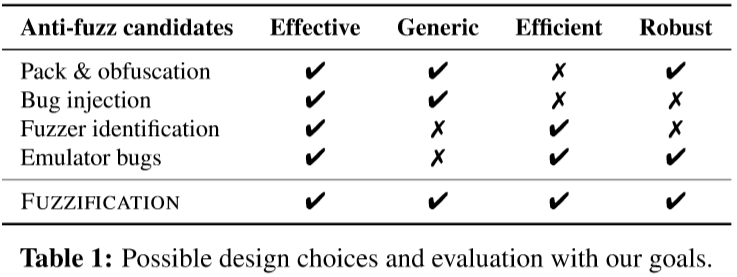
- Packing/obfuscation
- 可以阻止逆向 通用和鲁棒性
- 运行的高性能开销
- Bug injection:注入任意代码片段触发不可用的crash
- 额外的bookkeeping开销,并且对用户可能有未预料到的影响
- Fuzzer identification:监测fuzz进程
- 可以被很容易的通过修改进程名绕过 也不能针对所有的fuzz技术
- Emulator bugs:在动态检测工具中(模拟器)触发bug干扰fuzz
- 需要针对fuzzer,不通用
以上四个选择均不完全满足目标,所以有了fuzzification
设计概览
三项技术:SpeedBump, BranchTrap, and AntiHybrid
- SpeedBump:向cold path(正常执行很少使用,但fuzz经常用的路径)注入细粒度的延迟
- BranchTrap:构造了许多对输入敏感的分支,以诱使基于覆盖率的模糊器将其精力浪费在徒劳的路径上。同样,它有意地使代码覆盖中充满频繁的路径冲突,从而使模糊器无法识别触发新路径的有趣输入。
- AntiHybrid:将显式数据流转换为隐式数据流,以防止通过污点分析进行数据流跟踪,并插入大量伪造符号以在符号执行过程中触发路径爆炸.
系统结构如下:
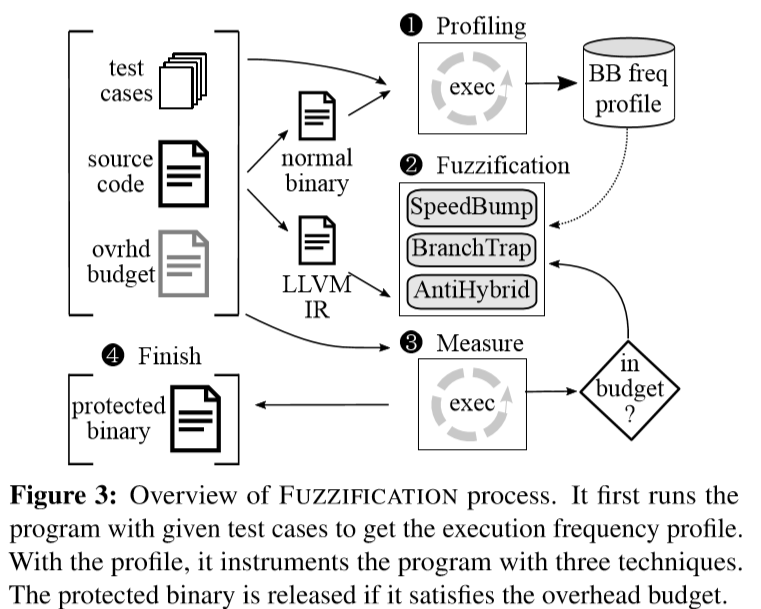
FUZZIFICATION依赖于开发人员确定适当的间接费用预算
- 编译程序以生成一个正常的二进制文件,并使用给定的正常测试用例运行它以收集基本块频率。频率信息中得知正常执行很少使用哪些基本块。
- 根据配置文件,将三种模糊化技术应用于该程序并生成一个临时的受保护的二进制文件
- 用给定的正常测试用例再次测量临时二进制文件的开销。如果开销超出预算将返回到步骤2,以减少程序的运行速度,例如使用更短的延迟和添加更少的工具。如果开销远低于预算开销,相应增加开销
- 生成受保护二进制程序文件
SpeedBump: Amplifying Delay in Fuzzing
观察发现fuzz执行经常落入错误处理(错误的magic bytes)等路径上,而正常程序却很少落入–这种路径称作cold path.
向这种路径上注入延迟。
先通过测试样例识别出cold path,然后将精心设计的延迟注入到最少执行的代码路径中。工具会自动确定注入延迟的代码路径数量以及每个延迟的长度,以便在正常执行过程中,受保护的二进制文件在用户定义的预算内就会产生开销。
基本块频率分析:FUZZIFICATION通过基本块频率分析识别cold path。
- 检测目标程序以在执行过程中对访问的基本块进行计数,并生成用于分析的二进制文件;
- 使用用户提供的测试用例,使用此二进制文件并收集每个输入访问的基本块。
- 分析收集的信息以识别很少由有效输入执行或从未执行的基本块。 这些块在延迟注入中被视为cold path
分析过程并不需要给定测试用例覆盖100%的合法路径,只需要其能触发常用的函数与功能。(可行性基于有经验的开发者一定会有一组用于覆盖常用功能的测试用例,如果开发者还有能触发不常用功能的测试用例更好)
可配置延迟注入:通过重复以下两步判定注入延迟的cold block的集合与每个延迟的长度
- 对最少执行的3%基本块注入30ms延迟
- 测试生成的二进制程序,如果没达到预期的开销,就回到第一步注入更多延迟,反之…
SpeedBump 选项:
- MAX_OVERHEAD:预期开销
- DELAY_LENGTH:延迟的范围,评估中选取的是10ms~300ms
- INCLUDE_INCORRECT:是否向错误处理中注入延迟,默认enable
- INCLUDE_NON_EXEC:指定是否向测试中从未执行中的基本块中注入延迟
- NON_EXEC_RATIO:同上,如果在没有大量测试集时有用
抗分析的延迟原语
不采用sleep等易被分析移除的简单延迟操作。采用算术操作,并且与原始的基本代码有联系。实际操作:基于并修改了CSmith(生成带有精致选项的随机和无错误代码片段),以生成具有数据依赖性和原始代码依赖性的代码,多次执行以找到延迟在某个指定时间的代码片段。 具体来说,将原始代码中的变量传递给生成的代码作为参数,产生一个生成的代码对原始代码进行引用,然后使用返回值修改原始代码的全局变量。跟原始代码产生数据依赖和控制流依赖,常用二进制分析工具不易处理。如图:

延迟原语安全性:使用CSmith和FUZZIFICATION确保生成的代码无bug。
能察觉错误处理块的fuzz:VUZZer与T-Fuzz之类的可以识别错误处理模块,并将其从代码覆盖计算中剔除,可能会对SpeedBump产生影响(与SpeedBump原理上相似)。但是SpeedBump不止针对错误处理块,并且有选项允许开发者忽略错误处理块处理,以关注很少执行功能块最大化效果。
BranchTrap: Blocking Coverage Feedback
通过插入大量的条件对输入的轻微改变敏感的分支,让fuzz掉入这些分支陷阱,基于代码覆盖的fuzz会在其中浪费大量资源。
伪造基于用户输入的假路径
伪造大量的条件跳转或间接跳转,注入原始程序。每个条件分支都基于输入的一些字节判断是否分支,间接跳转的目标取决于输入的计算结果。fuzz一旦触发了伪造的路径,尝试变异此输入时会触发更多的假路径,浪费更多的资源。
为了更高效,采取了四个措施:
- 假路径要足够多,让fuzz持续的挖出新路径,影响fuzz的执行
- 插入的假路径对正常执行消耗很小
- 插入的路径应该由用户输入确定,相同的输入走相同的路径(AFL这种模糊测试工具会检测并忽略掉不确定的路径/如果两个执行走了相同的路径,AFL会忽略掉这个输入)
实际实现中,BranchTrap使用了代码重用技术(类似于ROP)去设计实现BranchTrap。
BranchTrap with CFG Distortion
- 从程序编译过程中的汇编代码中收集函数的尾声
- 相同指令序列的函数尾声被分组到一个表
- 重写汇编代码保证函数从相应的跳转表中可以恢复其原来的尾声
- 将函数的尾声替换成同等功能的代码,确保与原程序功能相同
BranchTrap在运行时的表现:
- 对每个函数,计算其所有参数的异或值(对跳转表长度取余),作为跳转表的索引
- 访问跳转表获取函数尾声的正确地址
- 之后控制流转移至gadget执行后返回
好处:
- 有效:产生大量未产生的跳转,干扰覆盖率驱动的fuzz,并且每个输入的路径都不同,识别不出假路径
- 低开销:少于1%,主要是由于过程简单(存参数/异或/查jump地址/跳转到gadget)
- 鲁棒性:增加了分析识别并对程序打补丁的复杂性
Saturating Fuzzing State(让模糊测试器的状态饱和)
BranchTrap能够引入大量确定性分支基本块,一旦模糊器到达这些基本块,其覆盖范围表将很快被填满,之后模糊器将舍弃实际上探索有趣路径的输入。比如说,AFL维护一个固定大小的bitmap(即64KB)以跟踪边缘覆盖率。通过插入大量不同的分支,显著增加了bitmap冲突的可能性,减少了覆盖范围的不准确性。
对于AFL的情况,如图:
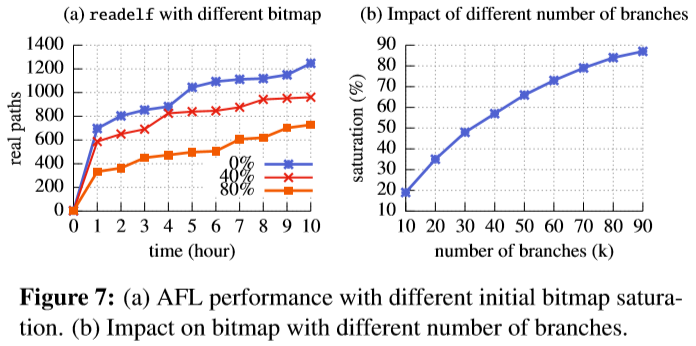
可以看到图(a)初始时bitmap覆盖的越多,发现路径的数量越少。
Fuzzers with collision mitigation:针对具有防碰撞功能的模糊测试器,比如CollAFL(通过为每个路径覆盖范围分配一个唯一的标识符(即在CollAFL的情况下为分支)来减轻覆盖范围冲突问题).
但这种方法并不会很好的破坏BranchTrap技术,原因有二:
- 当前的缓解冲突技术要求程序源代码在链接时间优化过程中分配唯一的标识符,但在本文所述威胁模型中攻击者只有被保护的二进制程序,而无法获得程序源代码或原始二进制文件
- 由于大容量存储的开销,这些模糊测试器仍然必须采用固定大小的内存存放代码覆盖记录。如果BranchTrap能将存储空间的90%饱和,那么CollAFL就只能将剩余的10%用于ID分配,模糊测试性能仍将受到显着影响。
Design Factors of BranchTrap
给开发者提供了接口去配置BranchTrap。
- 生成的假路径数量可以配置
- 上述BranchTrap是通过处理函数实现,如果函数很少的话,可以通过配置选项将基本块进行拆分
- 用于让覆盖范围饱和的注入的分支的大小也是可控制的,上图b可以看到分支与AFL的bitmap饱和率的关系,为了避免程序填充后太大,可以调整
- 为了防止代码大小超出预算,只在一个或两个最少执行的基本块注入大量分支???
AntiHybrid: Thwarting Hybrid Fuzzers
针对混和模糊测试(利用符号执行与动态污点的模糊测试)。
混合执行缺点
- 消耗量大量的资源
- 符号执行因为资源消耗大,大多数符号执行器无法运行至程序结束
- 动态污点分析无法跟踪隐性数据依赖(例如隐蔽通道,控制通道或基于定时的通道),为了覆盖 控制通道的数据依赖,动态污点分析引擎必须在条件分支之后将taint主动传播到任何变量,从而使分析更耗费且结果不太准确。
引入隐性数据依赖:将原始程序中的显式数据流转换为隐式数据流,以防止污点分析,图如下:
- FUZZIFICATION确定分支条件和有趣的信道(例如strcmp
- 根据变量类型注入数据流转换代码

图解:6-15行是隐性的数据流(一番操作后就没有污点了),阻碍动态污点分析;20行注入hash函数来迷惑符号执行器(判断相等的两边同时做了hash)
隐式数据流阻碍了对直接数据传播的数据流跟踪分析,但是无法通过差异分析来防止数据依赖性推断。最近的RedQueen通过模式匹配推断输入和分支条件之间的潜在关系,可以绕过隐式数据流转换。但是RedQueen要求在输入中显式的显示分支条件的值,可以通过简单的数据修改(例如将相同的常量值添加到比较的两个操作数中)轻易地弄虚作假。
让路径约束爆炸:针对符号执行器。为了使用符号执行来阻止混合模糊器,FUZZIFICATION注入多个代码块以故意触发路径爆炸。CRC处理
- 用两个操作数的hash值比较替换原本的值的比较
- 但是哈希函数通常会在程序执行中引入不可忽略的开销
- 利用轻量级的循环冗余校验(CRC)循环迭代来转换分支条件以减少性能开销。
- 虽然理论上讲,CRC在阻止符号执行方面不如散列函数那么强,但它也带来了显着的减慢
- 符号执行决定解决CRC约束,则由于复杂的数学运算,它通常会返回超时错误。
- QSym首次尝试解决我们注入的复杂约束时,它将因超时或路径爆炸而失败
- Qsym多次运行注入的代码,会识别出重复的基本块(即注入的哈希函数)并执行基本块修剪,决定不从中生成进一步的约束,而是将资源分配给新约束。之后,QSym很少会探索分支中的代码。
Evaluation
实现:6559行python代码,758行c++代码
- SpeedBump:实现为LLVM pass,在编译期间将延迟注入cold path
- BranchTrap:直接分析修改汇编代码
- AntiHybrid
- 使用LLVM pass导入路径爆炸功能
- 使用python脚本自动注入隐形数据依赖
目前在64位系统上支持全部特性;32位系统上不支持BranchTrap。
实验设计:
- FUZZIFICATION与四个先进的模糊测试器
- AFL QEMU模式
- HonggFuzz PT模式
- VUzzer 32
- Qsym AFL-QEMU
- 为了获得可重现的结果,试图消除模糊器的不确定因素:
- 禁用了实验机的地址空间布局随机化
- 为AFL强制采用确定性模式。
- 在HonggFuzz和VUzzer中保留随机性,因为它们不支持确定性模糊。
- 对FUZZIFICATION中的基本块配置使用了相同的测试集,并为不同的Fuzzer提供了相同的种子输入。
- 为每个目标应用程序执行代码检测和二进制重写时,我们使用了相同的FUZZIFICATION技术和配置,预先生成了FUZZIFICATION原语(例如10毫秒至300毫秒的SpeedBump代码以及具有确定性分支的BranchTrap代码
目标程序:
- LAVA-M数据集
- 九个经常用作测试的现实世界程序
- 四个来自Google fuzzer test-suite
- 四个来自binutils
- PDF阅读器MuPDF
- 在程序上进行了两组实验
- 九个现实程序用afl/Honggfuzz/Qsym跑,衡量FUZZIFICATION的影响(时间原因没做VUzzer 32)
- 编译了8个现实程序(没有MuPDF)
- 原始的
- 加了SpeedBump
- 加了BranchTrap
- 加了AntiHybrid
- full protection(三个技术结合)
- 对于MuPDF
- 原始的
- full protection(三个技术结合的)
- 编译了8个现实程序(没有MuPDF)
- 九个现实程序用afl/Honggfuzz/Qsym跑,衡量FUZZIFICATION的影响(时间原因没做VUzzer 32)
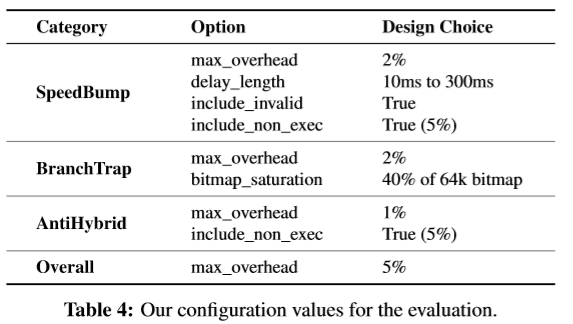
具体每项技术的配置如图:
处理后的程序
分析:
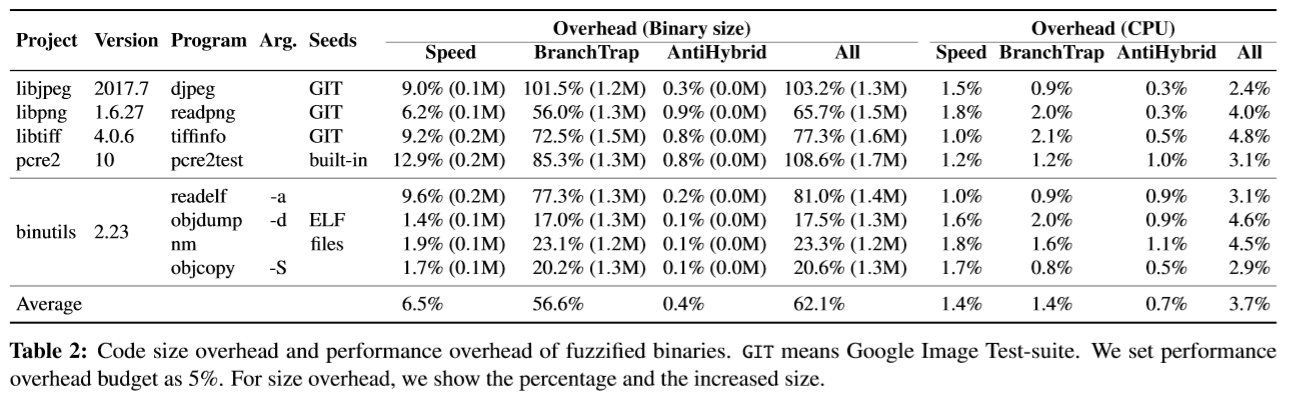
- 平均而言,二进制文件比原始二进制文件大62.1%,额外的代码主要来自BranchTrap技术
- 不同程序之间的额外代码大小几乎相同。因此,小型程序的大小开销很高,而大型应用程序的大小开销可以忽略不计。例如,LibreOffice应用程序的大小开销小于1%
- 但BranchTrap是可配置的,并且开发人员可以向较小的程序注入较少数量的假分支,以避免大开销
评估指标:代码覆盖率(指真实路径的)和特殊的crash
- 真实路径是原始程序中有的路径(去掉了假路径和初始种子触发的路径,专注于fuzz发现的)
- 特殊crash:在清楚的真实路径上导致程序崩溃的输入
减少代码覆盖
普通模糊测试器的影响
下图,fuzzification在afl-qemu上的效果(72小时),honggfuzz结果在附录: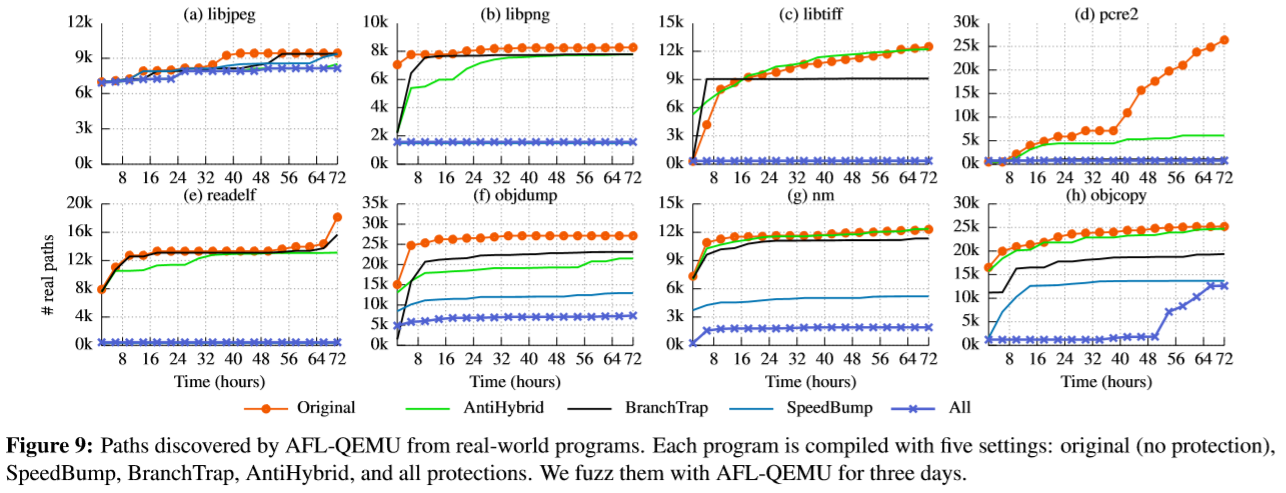
结果分析:平均在afl上减少了76%的真实路径发现,在honggfuzz上是67%。
- 对于AFL,减少率从14%到97%不等,而FUZZIFICATION减少了90%的libtiff,pcre2和readelf路径发现。
- 对于HonggFuzz,减少率在38%至90%之间,而FUZZIFICATION仅pcre2路径减少了90%以上
下图是每个技术在减小路径发现上的效果: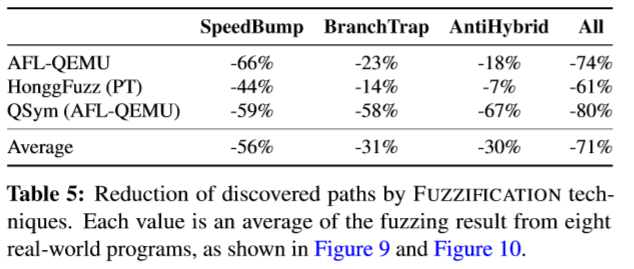
结果分析:SpeedBump可以最好地防御普通的模糊测试,其次是BranchTrap和AntiHybrid
分析较差的结果:在保护libjpeg应用程序方面效果不佳
- 将真实路径libjpeg的数量减少到AFL的13%,将HonggFuzz减少37%,而平均减少量分别为76%和67%。
- 分析了libjpeg上的模糊化,发现SpeedBump和BranchTrap无法有效地保护libjpeg。这两种技术仅在用户指定的开销预算中注入了九个基本块(对于SpeedBump为2%,对于BranchTrap为2%),这少于所有基本块的0.1%。为了解决此问题,开发人员可能会增加间接费用预算,以便FUZZIFICATION可以插入更多的障碍来保护程序。
混合模糊测试器的影响
在qsym上的实验结果如下图: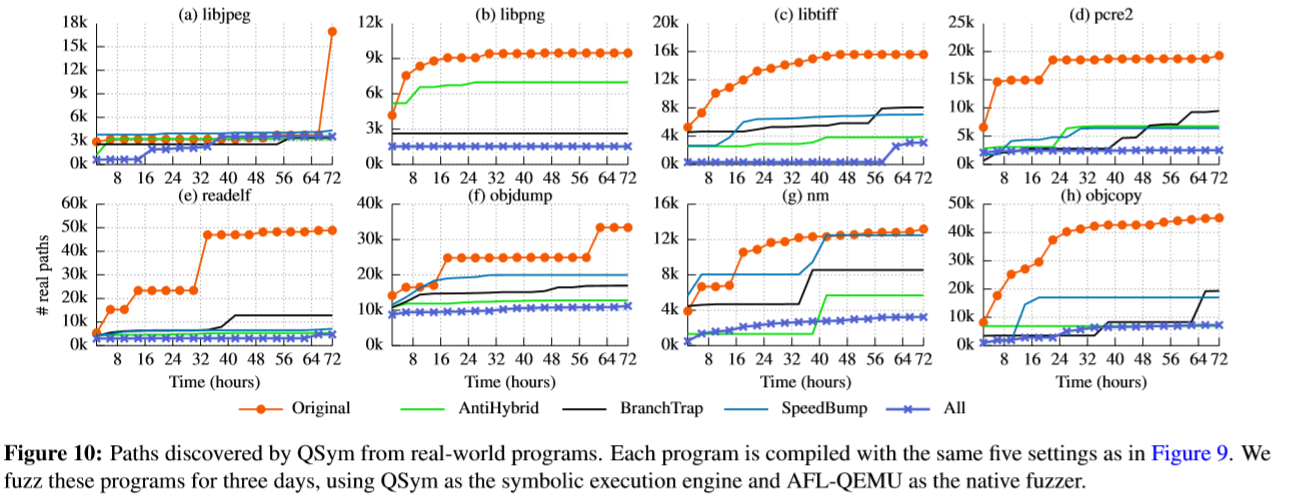
减少率在66%(objdump)到90%(readelf)之间变化。 libjpeg的结果显示了一个有趣的模式:QSym在最近8小时内从原始二进制文件中找到了大量真实路径,但是从任何受保护的二进制文件中都没有得到相同的结果。
各种技术的影响如上图:
AntiHybrid对混合模糊器的效果最佳(路径减少67%),其次是SpeedBump(59%)和BranchTrap(58%)。
与普通模糊测试结果对比:
AntiHybrid对QSym的影响最大(减少67%),对AFL(18%)和HonggFuzz的影响较小(7%)。借助模糊化技术,QSym相比普通的模糊器显示的优势较小,从44%降低至12%。
阻碍bug的发现
- 首先在四个binutils程序和LAVA-M上评估(使用了除了VUzzer外的所有模糊测试工具)
- 然后用VUzzer测试了LAVA-M(编译成32位程序,去除了BranchTrap因为这个技术只支持64位程序)
对真实程序的影响
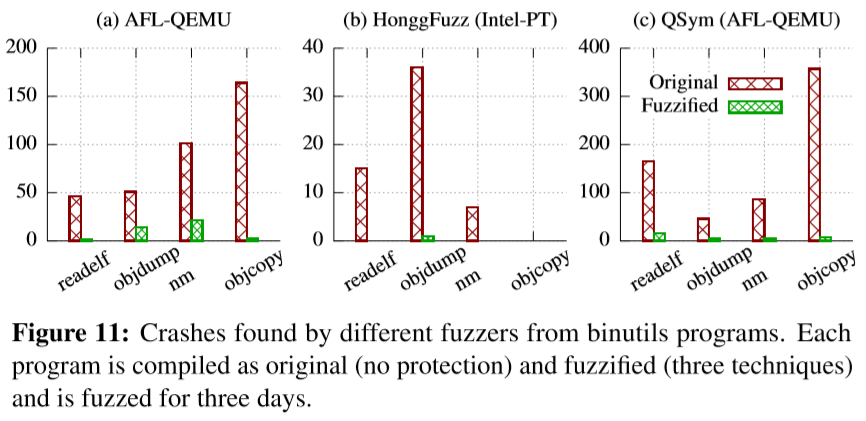
上图显示了72小时内三个模糊器发现的unique崩溃总数。FUZZIFICATION将发现的崩溃数量减少了93%,特别是AFL减少了88%,HonggFuzz减少了98%,Qsym减少了94%。
对LAVA-M数据集的影响
LAVA-M程序体积更小,操作更简单。如果对很少执行的二进制代码的1%注入1ms的延迟,则该程序的速度将降低40倍以上。要将FUZZIFICATION应用于LAVA-M数据集,需要更高的开销预算并应用更多细粒度的FUZZIFICATION。最后使用了微小的延迟原语(即10µs至100µs),将基本块检测的比例从1%调整为0.1%,减少了AntiHybrid的应用数量,并注入了较少的确定性分支以减少代码大小的开销。
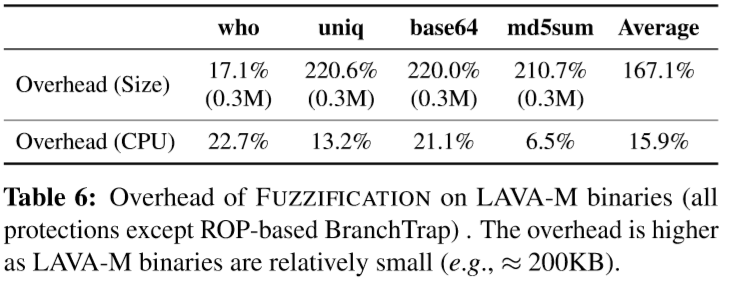
上图显示了使用FUZZIFICATION技术生成的LAVA-M程序的运行时和空间开销。在对受保护的二进制文件模糊测试10小时后,AFL-QEMU找不到任何崩溃。HonggFuzz从原始uniq二进制文件中检测到3个崩溃,没有从任何受保护的二进制文件中找到任何崩溃。下图是VUzzer和QSym的测试结果:
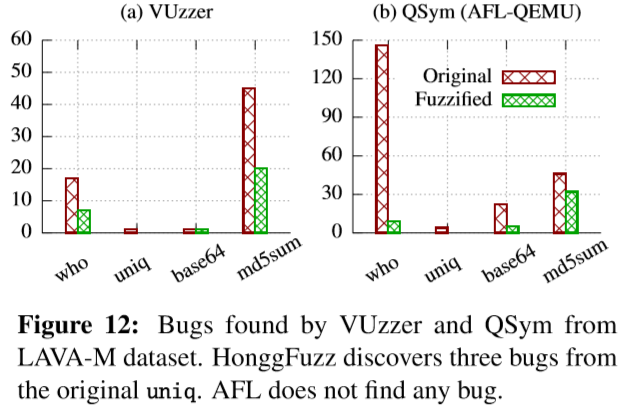
总体而言,对VUzzer发现的错误可以减少56%和对QSym减少78%
Anti-fuzzing on Realistic Applications(现实程序上的抗模糊测试)
为了测试FUZZIFICATION在大型现实应用中的实用性,选择了六个具有GUI界面并依赖于数十个库的程序。由于对大型程序和GUI程序进行模糊处理是一个众所周知的挑战性问题,因此这里的评估着重于测量FUZZIFICATION技术和功能的开销。
- 应用SpeedBump技术
- 只将慢速原语插入错误处理例程(缺少命令行界面(CLI)支持不得不跳过基本的块分析步骤)
- 应用BranchTrap技术
- 选择将大量的假分支注入到入口点附近的基本块中。这样,程序执行将始终通过注入的组件,以便可以正确地测量运行时开销
- 应用AntiHybrid技术
- 直接应用
- 对于每个受保护的应用程序,首先使用多个输入(包括给定的测试用例)手动运行它确认FUZZIFICATION不会影响程序的原始功能.
结果分析:FUZZIFICATION平均会引入5.4%的代码大小开销和0.73%的运行时开销。代码大小开销比以前的程序要小得多(即对于8个相对较小的程序与对于简单的LAVA-M程序(100%以上的大小开销))
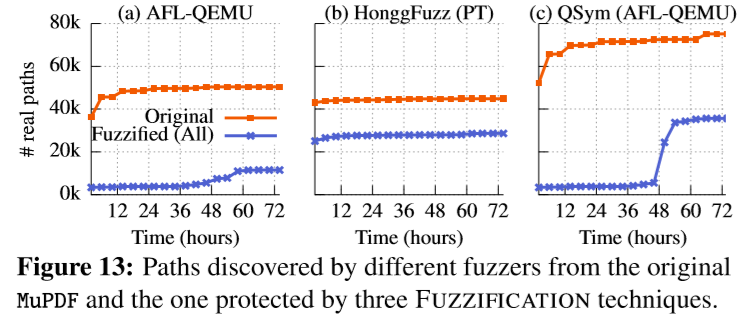
针对MuPDF的抗fuzz:评估了FUZZIFICATION在抵挡三种Fuzzer(AFL,HonggFuzz和QSym)方面的有效性。
由于经过72小时的模糊测试后,没有任何fuzz从MuPDF中发现任何错误。改为比较原始二进制文件和受保护二进制文件之间的真实路径数。 如下图,工具将总路径减少了55%,特别是AFL减少了77%,HonggFuzz减少了36%,QSym减少了52%。对于现实世界的模糊测试而言,从受保护的应用程序中查找错误更具挑战性。
Evaluating Best-effort Countermeasures
检查方法的鲁棒性。如图: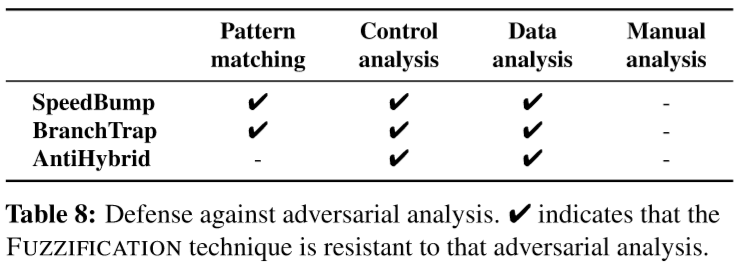
- AntiHybrid技术注入的代码例如哈希算法或数据流重构代码可以被攻击者检测到
- 解决该问题的一种可能方法是使用现有的diversity techniques来消除通用模式
- 控制流分析可以自动识别给定二进制文件中未使用的代码,从而自动将其删除(即消除无效代码)。但是,由于所有注入的代码都与原始代码交叉引用,因此该技术无法解决
- 数据流分析能够识别数据依赖性。作者在调试工具GDB中运行受保护的二进制文件,以检查注入的代码和原始代码之间的数据依赖关系,确认数据依赖关系始终通过全局变量,参数和注入函数的返回值存在
- 假想了一个可以分析解决所有技术的对手
最后,论文不考虑一个有能力的强大对手分析应用程序逻辑以发现漏洞的过程。
结论:手动分析最终可以通过评估代码的实际功能来识别并取消本文所述的技术。但是,由于注入的代码在功能上与正常的算术运算相似,并且对原始代码具有控制和数据依赖性,因此本文认为手动分析既耗时又容易出错。
总结
本文提出了一种对抗模糊测试的方法FUZZIFICATION,提出并实现了三种阻碍模糊测试的原理方法:
- SpeedBump(为延迟模糊测试的每次执行而注入延迟);
- BranchTrap(插入虚假分支以混淆代码覆盖范围的反馈);
- AntiHybrid(转换数据流以阻碍污点分析,并利用复杂的约束削弱符号执行)。
本文设计的抗模糊原语阻止攻击者绕过。实验评估表明,对于真实世界的二进制文件,本文的方法可以将路径探索减少70.3%,将bug的发现减少93.0%,对于LAVA-M数据集,可以将bug发现减少67.5%。