Jieba是基于统计的分词方法,jieba分词采用了动态规范查找最大概率路径,找出基于词频的最大切分组合。
Jieba
分词模式
Jieba有三种分词模式:
- 全模式:输出一个字串的所有分词
- 精准模式(默认):对句子的一个概率最佳分词
- 搜索引擎模式:提供了精确模式的再分词,将分词再次拆分为短词
分词方法
Cut(self,sentence,cut_all=False,HMM=True)
Cut方法接受三个参数:需要分词的字串,cut_all参数控制是否采用全模式,HMM参数用来控制是否使用HMMH模型;
Cut_for_search(self,sentence,HMM=True)
Cut_for_search接受两个参数:字串,是否使用HMMH模型,适用于搜索引擎构建倒排索引分词粒度较细
jieba.load_userdict(fileName)加载自定义的字典路径
Word2vec
Word2vec词向量模型:通过神经网络机器学习算法来训练语言模型,并在训练过程中求所对应的词向量的方法。
实例
选取语料文本,用jieba进行分词
这里选取的是金庸的小说天龙八部的全文,首先进行jieba分词,采用的是精准分词:
#encoding=utf-8
import sys
import re
import codecs
import os
import shutil
import jieba
import jieba.analyse
#导入自定义人物词典帮助分词
jieba.load_userdict("renwu.txt")
#删除原来的文件,创建并打开新文件
resName = "result.txt"
if os.path.exists(resName):
os.remove(resName)
result = codecs.open(resName, 'w','utf-8')
#语料文本
fileName='tlbb.txt'
source = open(fileName, 'r',encoding='utf-8')
#去标点符号,有点丑陋
line = source.readline().replace(',','').replace('。','').replace('《','').replace('》','').replace('/','').replace('?','').replace(':','').replace(';','').replace('‘','').replace('’','').replace('”','').replace('“','').replace('!','').replace('【','').replace('】','').replace('、','').replace('¥','').replace('%','').replace('*','').replace('-','').replace('=','').replace('+','').replace('&','').replace('……','').replace('#','').replace('@','').replace('~','').replace('·','').replace('`','').replace('!','').replace('$','').replace('^','').replace('_','').replace('{','').replace('}','').replace('[','').replace(']','').replace(':','').replace(';','').replace('<','').replace('>','').replace(',','').replace('.','')
while line != "":
line = line.rstrip('\n')
seglist = jieba.cut(line, cut_all=False)
output = ' '.join(list(seglist))
result.write(output + ' ')
#去标点符号,有点丑陋
line = source.readline().replace(',','').replace('。','').replace('《','').replace('》','').replace('/','').replace('?','').replace(':','').replace(';','').replace('‘','').replace('’','').replace('”','').replace('“','').replace('!','').replace('【','').replace('】','').replace('、','').replace('¥','').replace('%','').replace('*','').replace('-','').replace('=','').replace('+','').replace('&','').replace('……','').replace('#','').replace('@','').replace('~','').replace('·','').replace('`','').replace('!','').replace('$','').replace('^','').replace('_','').replace('{','').replace('}','').replace('[','').replace(']','').replace(':','').replace(';','').replace('<','').replace('>','').replace(',','').replace('.','')
else:
print('End file')
result.write('\r\n')
source.close()
这里加载了如下自定义词典,里面为小说中的一些人物名和专有词以帮助分词:
段誉
大理
皇储
皇太弟
镇南王
大将军
段正淳
世子
段延庆
刀白凤
大理
宣仁帝
木婉清
秦红棉
段正淳
发妻
郡主
贵妃
娘娘
宪宗
皇后
萧峰
萧远山
乔峰
丐帮
帮主
辽国
大王
楚王
雁门关
阿朱
姑苏慕容
阮星竹
虚竹
虚竹子
逍遥派
掌门
天山
缥缈峰
灵鹫宫
西夏
驸马
梦郎
粉面郎君
武潘安
李清露
王语嫣
李青萝
锺灵
甘宝宝
晓蕾
李清露
阿紫
段正明
华赫艮
范骅
巴天石
朱丹臣
褚万里
古笃诚
大理国
傅思归
高升泰
高泰明
过彦之
崔百泉
本因
大师
本观
本相
本参
枯荣
长老
黄眉僧
鸠摩智
无崖子
李秋水
天山童姥
梅剑
兰剑
竹剑
菊剑
余婆
石嫂
符敏仪
程青霜
岳老三
叶二娘
段延庆
云中鹤
柯百岁
玄悲
禅师
河北
骆氏
三雄
章虚道人
单叔山
单季山
单小山
谭公
谭婆
赵钱孙
王维义
鹤云道长
单正
方大雄
杜二哥
乔三槐
乔婆婆
玄苦
扫地神僧
玄慈大师
神山上人
观心
道清
觉贤
融智
神音
五叶
智光
破嗔
破痴
玄痛
玄难
玄寂
玄因
玄惭
玄渡
玄愧
玄止
玄念
玄净
玄垢
玄生
玄灭
玄鸣
玄石
玄澄
慧方
慧镜
慧真
慧观
慧轮
青松
止清
止湛
止渊
缘根
苏星河
琴魔
康广陵
棋颠
范百龄
苟读
画圣
吴领军
神医
薛慕华
冯阿三
石清风
李傀儡
桑土公
玄黄子
章达夫
端木元
黎夫人
乌老大
崔绿华
卓不凡
钦岛主
霍洞主
司马岛主
于洞主
安洞主
九翼道人
区岛主
云岛主
珠崖大怪
珠崖二怪
哈大霸
汪剑通
马大元
徐冲霄
奚山河
吴长风
陈孤雁
宋长老
吕章
白世镜
全冠清
蒋舵主
张全祥
方舵主
李春来
刘竹庄
慕容复
慕容博
蔡庆图
阿碧
包不同
风波恶
公冶乾
邓百川
马五德
龚光杰
褚师弟
容子矩
干光豪
葛光佩
司空玄
在代码中用了大量的replace进行标点符号的去除,然后进行分词后写入结果文件result.txt。
分词结果如下图:

word2vec向量化
首先加载语料,然后用word2vec.Word2Vec进行训练,最后对模型进行保存
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s',level=logging.INFO)
sentences=word2vec.Text8Corpus("result.txt")
model=word2vec.Word2Vec(sentences,size=200)
print(model['萧峰'])
print(model.similarity("慕容复","萧峰"))
print(model.most_similar("萧峰",topn=10))
print(model.doesnt_match("段誉 虚竹 萧峰 大师".split()))
model.save("tlbb.model")
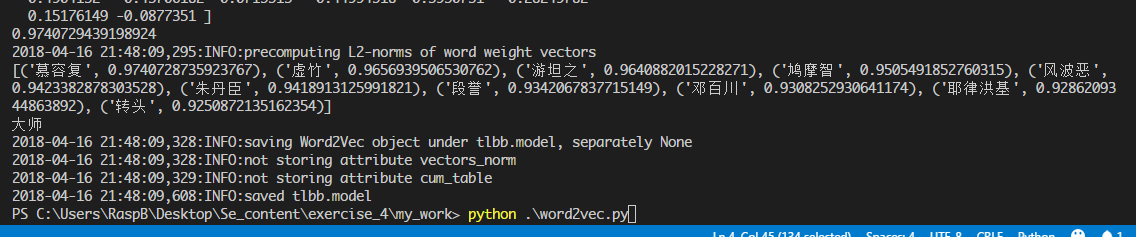
- print(model[‘萧峰’])打印出来萧峰的向量矩阵;
- print(model.similarity(“慕容复”,”萧峰”))打印出两者的相关程度;
- print(model.most_similar(“萧峰”,topn=10))打印与其相关最高的前十个词;
- print(model.doesnt_match(“段誉 虚竹 萧峰 大师”.split()))打印出四者中最不相关的一个;
- 最后将模型保存为tlbb.model以备后续使用。
运行结果
萧峰的向量矩阵:
其余三个输出信息: