Scrapy是一个python开发的快速高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。广泛用于数据挖掘、监测和自动化测试。
Scrapy 框架结构
- 引擎:用来处理整个系统的数据流,触发事务;
- 调度器:调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎;
- 下载器(Downloader):下载器负责获取页面数据并提供给引擎,而后提供给spider;
- 爬虫(Spiders):Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站;
- Item Pipeline: Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中);
- 下载器中间件(Downloader middlewares):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能;
- Spider中间件(Spider middlewares): Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能;
数据流(Data flow)
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
实例–爬取豆瓣电影top250
首先用scrapy生成工程文件
scrapy startproject DoubanMovie
文件夹结构如下:
scrapy.cfg: 项目的配置文件。
DoubanMovie /: 该项目的python模块。之后您将在此加入代码。
DoubanMovie /items.py: 项目中的item文件。
DoubanMovie /pipelines.py: 项目中的pipelines文件。
DoubanMovie /settings.py: 项目的设置文件。
DoubanMovie /spiders/: 放置spider代码的目录
根据basic模板生成爬虫
scrapy genspider Doubanmovietop250 movie.douban.com
改写items.py文件
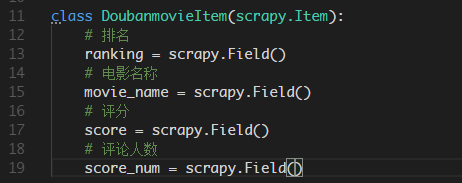
spider改写
为了防止爬虫检测,先将请求头进行改写,加入user-agent信息,生成新的头部:

在parse中加入对response的解析代码.
分析豆瓣电影榜的结构,可以看到,其存放榜单的结构如下:
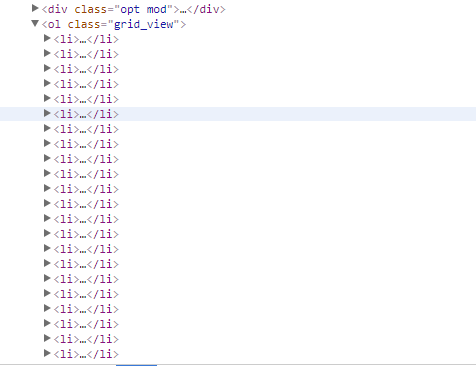
找到每个li对应的xpath进行解析后存入items:

对应后面的页面,查找到下一页网址在源代码中的位置:
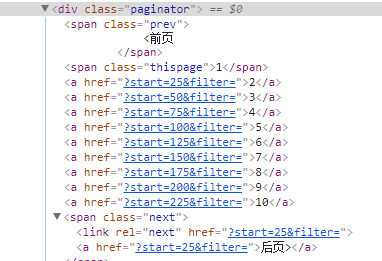
用xpath解析出来进行下一次的循环爬取:

settings.py设置
ROBOTSTXT_OBEY = True 是否遵守robots.txt
CONCURRENT_REQUESTS = 16 开启线程数量,默认16
AUTOTHROTTLE_START_DELAY = 3 开始下载时限速并延迟时间
AUTOTHROTTLE_MAX_DELAY = 60 高并发请求时最大延迟时间
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
以上几个参数对本地缓存进行配置,如果开启本地缓存会优先读取本地缓存,从而加快爬取速度.
运行
scrapy crawl douban_movie_top250 -o douban.csv
这里-o表示输出到文件,后接文件名,scrapy会根据文件后缀选择相应格式,这里为csv。
爬取结果:
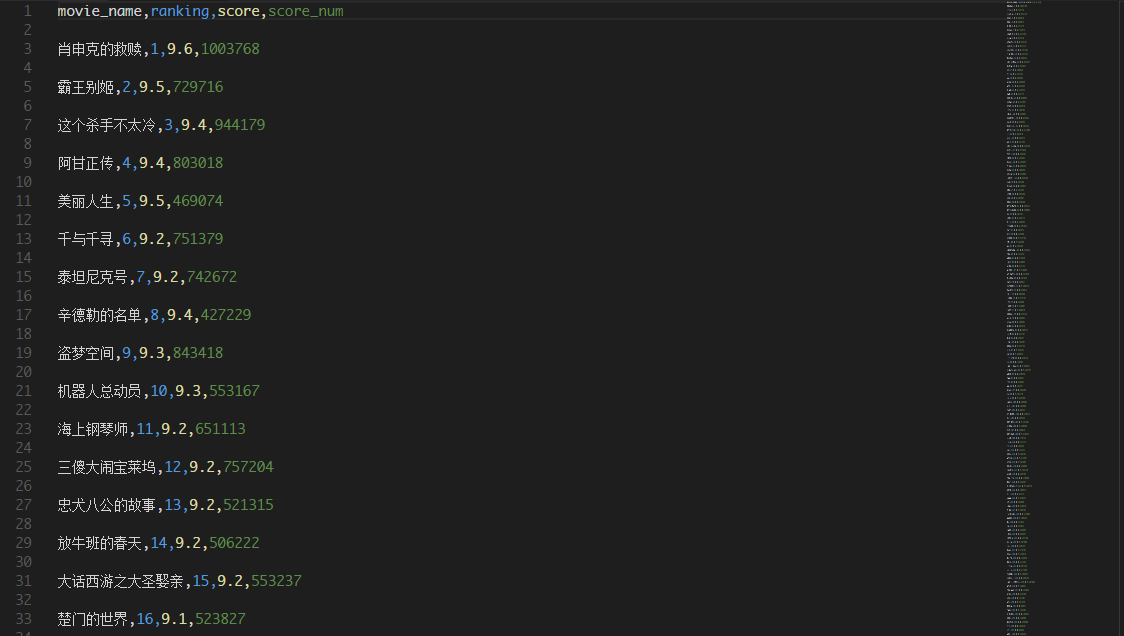
附spider部分完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from DoubanMovie.items import DoubanmovieItem
class Doubanmovietop250Spider(scrapy.Spider):
name = 'douban_movie_top250'
allowed_domains = ['movie.douban.com']
#start_urls = ['https://movie.douban.com/top250']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
item = DoubanmovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath('.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath('.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath('.//div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
item['score_num'] = movie.xpath('.//div[@class="star"]/span/text()').re(r'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)